Beyond the Hype, Toward Reliability: Building a Reliable, Offline AI Analyst for Advanced Cybersecurity
- Intro
- High Level Design
- Threat Investigation Flow
- Analyst’s Interaction with the Agent (Inference Flow)
- Key Takeaway
Intro
While many are showcasing the impressive capabilities of AI agents, few are addressing the more difficult challenge: ensuring reliability and correctness, especially in mission-critical fields like cybersecurity. As an architect involved in every stage of the software lifecycle, from brainstorming with hype-induced stakeholders to breaking things down for implementation, or even rolling up my sleeves and coding myself, I sometimes feel like the old guy in the room, pushing back against the excitement to preserve concepts that now seem uncool: reliability, correctness, security, and scalability.
When someone excitedly references an innovative proof of concept that has little chance of surviving in a real-world, production-grade environment with, “But I read it somewhere, it’s possible,” I like to reply, “I can give you my opinion in writing too, if that helps.”
That said, I’m a strong advocate for agents, agentic workflows, and the transformative potential of LLMs. I genuinely believe they can streamline many, if not most, workflows, from writing code to editing blog posts (as I’ll gladly admit). This is true, provided that LLMs and agents are used correctly and within the bounds of their capabilities and limitations, even though those boundaries are expanding almost daily.
As an advocate, I pushed hard to introduce LLM-based features into the products I work on, one of which is a cybersecurity agent. As expected, while I was the one enthusiastically pitching the idea, I was also the one tempering expectations about what agents (or at least the LLM-based parts of the agents) can do reliably and consistently, and at a near-human level. This is especially important given that the cyberattacks our product aims to detect are highly advanced and sophisticated, far beyond simple signature- or query-based detection. In this context, an agent with even a 15% error or hallucination rate does more harm than good. One wrong recommendation can lead to missed threats, wasted investigation time, or worse, eroded trust in the system altogether.
Agent Requirements and Scope
So, after weighing market, business, financial, and technical considerations, the final scope of the agent was defined as follows:
-
On-premise operation
The agent must function entirely offline, without internet access. -
Minimal hardware requirements
It should run on modest infrastructure, requiring no more than an L4 GPU with 24GB of memory. -
High reliability and consistency
Its performance should match or exceed that of an experienced cybersecurity expert, with a low error rate and no hallucinations. -
Support for advanced and general investigations
The agent must be capable of investigating sophisticated threats that require domain-specific knowledge, as well as performing broader, more generic analyses. -
Actionable guidance for humans
For each threat it handles, the agent should provide clear, per-threat investigation guidelines to help human analysts evaluate its findings.
With these requirements in mind, let’s dive into the agent’s architecture and how it operates.
High Level Design
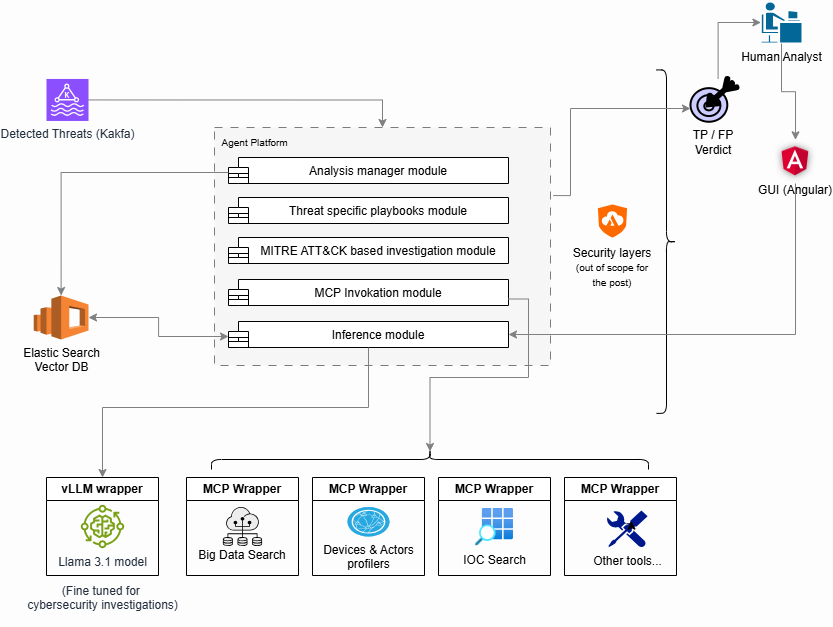
To better understand how the agent operates, here’s a high-level overview of its core modules and how they interact within the system:
Our advanced threat detection analytics produce potential threats detected within the monitored network or endpoints.
(Note: the underlying architecture, analytics runtime details, and infrastructure setup are out of scope for this post.)
These threats are written to Kafka, from which the agent platform consumes them and invokes the following modules:
- Analysis Manager Module
Orchestrates the threat investigation process:- Manages investigation queues
- Handles exceptions
- Coordinates execution between threat-specific logic and generic logic based on the MITRE ATT&CK framework
- And more
-
Threat-Specific Playbooks
The threats we detect often require advanced, use-case-specific investigation.
These investigations can be heuristic, ML/deep learning-based, LLM-based, or a combination of all.
While I can’t share full details for obvious reasons, you can assume this module contains dedicated logic specifically designed to analyze complex threats posed by advanced actors. -
MITRE ATT&CK-Based Investigation Module
In parallel with the threat-specific playbooks, this module executes investigation flows based on the detected MITRE ATT&CK tactics and techniques.
Like the playbooks, it supports heuristic, ML/deep learning, and LLM-based investigations. -
MCP Invocation Module
Responsible for invoking various tools available in the environment (e.g., big data search), either during automated investigations or via manual analyst requests. -
RAG Data Store
The results of all investigations are saved into an Elasticsearch-based vector database, enabling Retrieval-Augmented Generation (RAG) for downstream queries. -
Inference Module
Handles requests from end users, retrieves relevant context via RAG from Elasticsearch, and sends the final prompt to the model running on top of vLLM.
Additionally, it can translate human analysts’ follow-up questions, expressed in natural language, into corresponding investigation actions, which are then executed via MCP invocations. -
Fine-Tuned LLaMA 3.1 Model
In addition to the agent platform, we run vLLM with a fine-tuned LLaMA 3.1 8B model.
The fine-tuning process is out of scope for this post, but you can assume the model is trained on both generic cybersecurity knowledge and investigation methodologies aligned with the MITRE ATT&CK framework, using the tools available in the system (e.g., big data search, behavioral profiles, etc.). -
Tools with MCP Servers as Interfaces
We also have multiple services wrapped by MCP servers, which standardize access to tools and services invoked by the LLM, traditional ML/deep learning modules, or heuristic logic.
While invoking MCP from standard APIs may be considered unorthodox, this engineering choice allows us to avoid maintaining multiple interfaces for the same functionality.
It may not follow traditional best practices, but it’s a practical trade-off, favoring reduced maintenance and faster development cycles, which are crucial considerations in any architectural decision. - GUI (User Interface)
This is what the user sees. It allows monitoring of the list of threats, viewing the agent’s TP/FP verdicts, and reviewing the agent’s suggested next steps.
The user can also request additional information or invoke tools using natural language (e.g., “Run a search for this IP address” or “Get me the behavioral profile of this device”).
Threat Investigation Flow
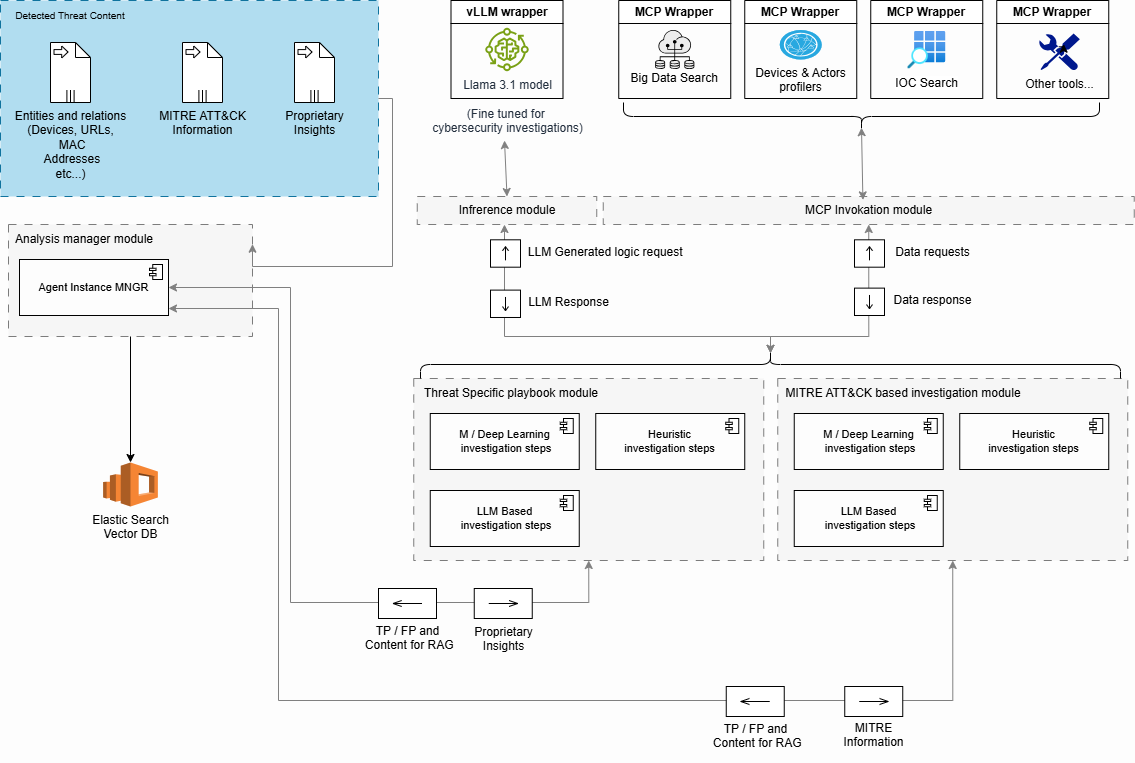
Threat Contents
For security reasons, I can’t share the exact contents of the threat data we receive.
However, at a high level, each threat typically contains (among other things):
- Related entities (e.g., devices, IPs, URLs, MAC addresses, etc.) and the relationships between them
- MITRE ATT&CK information such as used tactics and techniques in the attack
- Proprietary insights generated by ML/DL algorithms
Analysis Manager Module
Each threat is inserted into Kafka and consumed by the Analysis Manager Module.
As previously explained in the high-level flow section, this module handles administrative tasks such as:
- Managing investigation queues
- Routing threats to the appropriate investigation modules
- Handling exceptions and errors
- Inserting investigation results into the Vector database
- Exposing metrics
- And more
Threat-Specific and MITRE ATT&CK Investigation Modules
Both the threat-specific and MITRE ATT&CK-based investigation modules are triggered by the Analysis Manager Module.
Each investigation module performs a series of investigative steps, typically falling into one of three categories:
-
Machine or Deep Learning Investigation Steps
Example: Using an LSTM model to detect unusual network activity by comparing current behavior to prebuilt network profiles of the entities involved in the threat. -
Heuristic Investigation Steps
Example: Identifying a suspicious pattern such as multiple failed login attempts originating from a new country. -
LLM-Based Investigation Steps
Example: Understanding the scope of the threat based on previous investigation steps and the cybersecurity knowledge base the model was fine-tuned on, and generating a list of recommended next steps based on knowledge of existing tools in the system and their capabilities.
Deliberate Limitation of LLM Capabilities Within the Agent
As you can see, the LLM has limited influence on the final true positive/false positive (TP/FP) verdicts, and we do not rely on it to generate insights about complex and constantly evolving threats.
What we can do, however, is leverage the model after more controlled, AI-based (or not) and reliable detection methods have identified a threat. Once we understand where a threat fits within the cyber attack lifecycle, the LLM component can assist in:
- Filling up gaps in the investigation process, based on the knowledge it was fine-tuned on
- Suggesting next steps based on the current phase in the attack lifecycle, using methodologies it was fine-tuned on (curated by real experts) and its knowledge of the available tools in the system
- Filling gaps in the analyst’s knowledge (also based on the cybersecurity knowledge base it was fine-tuned on)
- Guiding the use of existing tools to gather supporting evidence, enrich context, or check external sources
The key point is that the LLM component of the agent should only do what it was trained to do, no more, no less.
Yes, it may not sound glamorous, and it won’t generate hype , but as long as the agent’s output is reliable, consistent, accessible in natural language, and delivered at minimal cost, the end user won’t care how flashy or cutting-edge the underlying technology is.
MCP and Inference Modules
These modules serve as interfaces used by the investigation components to invoke tools or send requests to the LLM model.
They are responsible for gathering additional evidence, performing queries, enriching context, and handling other tasks required during the execution of the investigation logic.
Investigation Output -> Inference Input
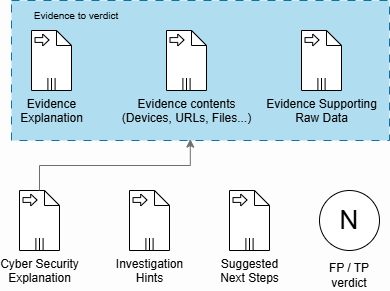
The investigation’s findings are stored in a vector database and retrieved via RAG during inference whenever an analyst interacts with the agent. The output is designed to provide a 360° view of the threat, covering both technical details and broader cybersecurity context.
-
True-Positive / False-Positive Verdict
A determination of whether the detected threat is a true positive or a false positive, with an associated confidence score. - Evidence Supporting the Verdict
Detailed information to support the verdict, including:- Evidence Explanation: A natural language summary and detailed explanation of the evidence
- Evidence Content: A graph of related entities (files, URLs, devices, etc.) and their interactions within the threat context (for example, a device contacting a URL and then uploading a file)
- Raw Data: Sample extracts from the data lake that validate the evidence and illustrate the entities involved
-
Cybersecurity Explanations
Contextual domain knowledge for analysts who may not be familiar with every technique, tactic, or tool used by adversaries. This section explains relevant attack methods and recommended defenses for the specific threat. -
Investigation Hints
Suggestions for informative questions, prompts, and tool invocations to ask the agent to help the analyst gather more information or clarify the investigation’s findings. - Next Steps
A list of recommended actions for the analyst, such as escalation, remediation, or further investigation.
To show the internal workflow - what each stage does and where we leverage the LLM to generate insights - here is a table mapping each output element to its source.
| Content Type | Sources |
|---|---|
| True-Positive / False-Positive Verdict | Investigation playbooks leveraging ML/DL models (High Impact), heuristics (High Impact), LLM insights (Low Impact) |
| Evidence Content | Various tools invoked via MCP from the investigation playbooks |
| Evidence Explanation | LLM |
| Raw Data | Big data tools invoked via MCP from the investigation playbooks |
| Cybersecurity Explanations | LLM |
| Investigation Hints | LLM |
| Next Steps | LLM |
Analyst’s Interaction with the Agent (Inference Flow)
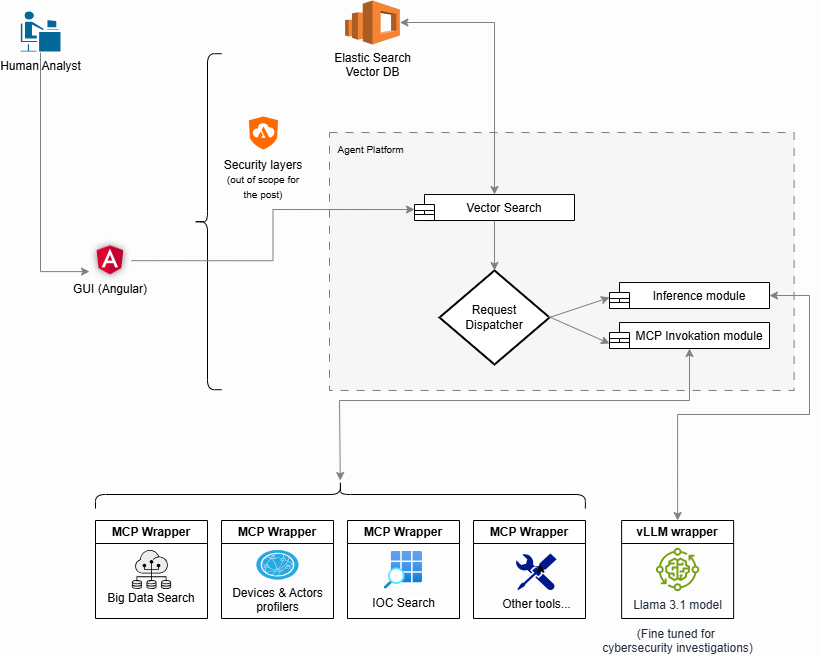
The inference flow is pretty straightforward. The analyst interacts with the agent platform via the GUI. The content and context of the request is arriving to the vector search module which extracts the relevant data from the output of the investigation flow. After that, the retrieved content and the request is pipelined trough a request dispatcher which decides whether to proxy the request to inference since it is only a question, to MCP invokation module since it is a request to run tool(s), or both.
Slightly Cheating to Avoid Semantic Mismatch
Semantic search can struggle with semantic mismatch, returning results that miss the true intent. Because our agent focuses on one threat at a time, we strive to keep the investigation output small enough to fit entirely within the model’s context window. During RAG, we retrieve and inject the full output whenever possible. If the output is too large, we fall back to retrieving only the most relevant portions related to that specific threat.
Key Takeaway
In workloads where reliability and consistency are key, at least in our approach, we cannot offload the core business logic to LLMs. This is especially true for small models running on-premise.
This is why orchestration and the most heavy core business logic, such as deciding on FP/TP, are performed by controlled components with carefully tested ML/DL models and heuristic flows (with only slight impact from LLMs), while the more peripheral components, like invoking tools, providing additional cybersecurity context, or summarizing information, are handled by LLMs.
IMO, this approach is a good balance for incrementally transitioning critical workloads into the agentic era without compromising reliability and consistency.
Perhaps at some point we will be able to offload the core business logic to LLMs, but for now, we are not there yet.