Leverage deep learning using AWS Rekognition and surveillance cameras to analyze customer satisfaction and emotions from sales representatives interactions
This post was written some time ago, and its content and code may be outdated or no longer aligned with current industry standards. Please proceed with caution. :-)
- Intro
- Prerequisites
- Aggregating faces and facial expressions (emotions) data from a video
- Extracting employees (sales representatives) from the general pool of faces
- Detecting whether a customer interacting with an employee
- Calculate employee performance
Intro
Imagine a bustling retail store with customers browsing, interacting with products, and engaging with staff.
What if the store could gain insights into how customers feel during these interactions and identify the most effective sales representatives?
By leveraging surveillance cameras and AWS Rekognition, stores can analyze and gain insights into customer satisfaction and behavior.
Correctly analyzing customer emotions can provide valuable insights into which areas should be improved to increase both customer satisfaction and sales.
AWS Rekognition is a powerful deep learning tool from AWS that can analyze images and videos.
It can be used to detect and track faces, analyze facial expressions and facial attributes, detect objects and landmarks, and many other capabilities.
This is just one of many use cases for AWS Rekognition; it can also be used for security surveillance, content moderation, user engagement analysis, and many other applications.
I will use Python with Boto3, but AWS has libraries for nearly every major programming language.
A quick yet important note: this is not production-ready code.
It lacks error validation, scalability and efficiency considerations, testability, and other best practices that were omitted for simplicity’s sake.
Additionally, the algorithm is simplified since the main goal is to demonstrate AWS Rekognition’s capabilities and not to provide a production-ready solution.
Think of it as a hackathon-level code and algorithm.
Prerequisites
- Make sure you have the
boto3andcv2Python libraries installed. - You need an AWS account and an
IAM userwith the necessary permissions to use Rekognition andS3. - You need an
S3 bucketto store the video file from the camera. Although it is possible to create real-time analysis with real-time streaming, for simplicity, we will use a simple video file. - Upload the video file you want to analyze to the
S3 bucket. - A local folder with pictures (e.g., employee tags) of sales representatives that will be used to identify them in the video. For simplicity, the file name will indicate the employee’s name.
Aggregating faces and facial expressions (emotions) data from a video
The first step is to analyze the entire video and extract all the faces and facial expressions from it. This data will serve as the basis for further analysis and insights. To achieve that, we will follow these steps:
- Create a face detection job and collect the results
- Aggregate the detected faces for a given timestamp
Detecting faces and collecting results
import boto3
# create rekognition client
rekognition = boto3.client('rekognition')
# define S3 bucket and key for the video, it will also be used later
s3_bucket = 'Name of the S3 bucket you created'
s3_key = 'S3 object key name of the video you uploaded'
# create a job
def start_face_detection_job():
response = rekognition.start_face_detection(
Video={
'S3Object': {
'Bucket': s3_bucket,
'Name': s3_key
}
},
FaceAttributes='ALL'
)
return response['JobId']
face_detection_job_id = start_face_detection_job()Now, we need to monitor the job and collect the output.
In a real-world scenario, you would probably use a more refined method than the one in this example.
For instance, the Rekognition API allows requesting notifications via the NotificationChannel parameter, so you can set an SNS topic to be notified when the job is completed.
This can trigger a Lambda function to process the results.
In our case, for simplicity, we will just create a function to poll the job status every 10 seconds until it is completed (or failed).
def get_face_detection_job_res():
while True:
# invoke the get_face_detection API and get the status
response = rekognition.get_face_detection(JobId=face_detection_job_id)
status = response['JobStatus']
# if the job failed than raise an exception and kill the process
if status == 'FAILED':
raise Exception('Job failed')
# if the job is completed successfully return the response
if status == 'SUCCEEDED':
return response
# if the job is still in progress, wait 10 seconds and poll again
time.sleep(10)
face_detection_job_res = get_face_detection_job_res()After the job is done, the result might be paginated.
In this case, you’ll receive a NextToken in the response, which you’ll need to use to page through the results.
Let’s create a function for that:
def process_face_detection_results(response):
next_token = response.get('NextToken')
# If not paginated, simply return the faces
if not next_token:
return response['Faces']
# If paginated, iterate through the pages and then return the faces
faces = []
while True:
paginated_response = rekognition.get_face_detection(JobId=face_detection_job_id, NextToken=next_token)
faces.extend(paginated_response['Faces'])
next_token = paginated_response.get('NextToken')
if not next_token:
break
return faces
faces = process_face_detection_results(face_detection_job_res)faces will contain an array of detected faces in a video frame, with the timestamp of the frame:
[
{
'Timestamp': 123,
'Face': {
'BoundingBox': {
'Width': ...,
'Height': ...,
'Left': ...,
'Top': ...
},
'Emotions': [
{
'Type': 'HAPPY',
'Confidence': 95.0
}....
],
....
'Pose': {
'Roll': ...,
'Yaw': ...,
'Pitch': ...
},
}
},
{
'Timestamp': 456,
'Face': {
'BoundingBox': {
'Width': ...,
'Height': ...,
'Left': ...,
'Top': ...
},
'Emotions': [
{
'Type': 'SAD',
'Confidence': 95.0
}....
],
....
'Pose': {
'Roll': ...,
'Yaw': ...,
'Pitch': ...
},
}
},
{
'Timestamp': 456,
'Face': {
'BoundingBox': {
'Width': ...,
'Height': ...,
'Left': ...,
'Top': ...
},
'Emotions': [
{
'Type': 'SAD',
'Confidence': 95.0
}....
],
....
'Pose': {
'Roll': ...,
'Yaw': ...,
'Pitch': ...
},
}
}
]At this point, let’s ignore what each property means; we will discuss it later.
Aggregating detected faces for a given timestamp
Now, let’s aggregate the face objects per timestamp.
from collections import defaultdict
def aggregate_faces_by_timestamp():
aggregated_faces = defaultdict(list)
for item in faces:
timestamp = item['Timestamp']
face = item['Face']
aggregated_faces[timestamp].append(face)
return aggregated_faces
aggregated_faces = aggregate_faces_by_timestamp()Now aggregated_faces will contain array of faces objects per timestamp.
{
'123': [ {...all the face objects in timestamp 123} ],
'456': [ {...all the face objects in timestamp 456} ],
}Extracting employees (sales representatives) from the general pool of faces
Before we can analyze customer satisfaction related to the sales representatives, we need a way to differentiate between the sales representatives and the customers. Here is the process to do this:
- Create a
collectioninRekognition. - Index our employee pictures to the collection.
- Run a face search on this collection to identify the employees in the video.
- Tag employees in the generic faces (
aggregated_faces) collection object.
Creating a collection and indexing employees pictures
collection_id = 'employees_collection'
def create_and_index_collection():
# create a collection
response = rekognition_client.create_collection(CollectionId=collection_id)
# iterate over the employees pictures and index them in the collection
for filename in os.listdir(employees_folder):
image_path = os.path.join(employees_folder, filename)
with open(image_path, 'rb') as image_file:
response = rekognition_client.index_faces(
CollectionId=collection_id,
Image={'Bytes': image_file.read()}, # the image is the image bytes
ExternalImageId=os.path.splitext(filename)[0], # id is the filename without the extension
DetectionAttributes=['ALL']
)Detecting employees in the video
Now, let’s run a face search on the video in the S3 bucket to identify the employees in the collection.
The process is similar to the previous face detection we created.
- Create a job
- Monitor the status
- Once done, paginate through the results
Let’s start by defining a function for the employees’ face search:
def start_employee_search():
response = rekognition_client.start_face_search(
Video={'S3Object': {'Bucket': s3_bucket, 'Name': s3_key}},
CollectionId=collection_id
)
return response['JobId']
employee_search_job_id = start_employee_search()Now, let’s monitor the job status similar to what we previously did:
def get_employee_search_res():
while True:
# invoke the get_face_detection API and get the status
response = rekognition.get_face_search(JobId=employee_search_job_id)
status = response['JobStatus']
# if the job failed than raise an exception and kill the process
if status == 'FAILED':
raise Exception('Job failed')
# if the job is completed successfully return the response
if status == 'SUCCEEDED':
return response
# if the job is still in progress, wait 10 seconds and poll again
time.sleep(10)
employee_search_res = get_employee_search_res()And finally iterate through the pages of the result with NextToken:
def process_employee_search_results(response):
next_token = response.get('NextToken')
# If not paginated, simply return the faces
if not next_token:
return response['Persons']
# If paginated, iterate through the pages and then return the faces
employees = []
while True:
paginated_response = rekognition.get_face_search(JobId=employee_search_res, NextToken=next_token)
persons.extend(paginated_response['Persons'])
next_token = paginated_response.get('NextToken')
if not next_token:
break
return employees
employees = process_employee_search_results()Now, employees variable will contain an array of Person objects:
[
{
'Timestamp': 123,
'Person': {
......
'BoundingBox': {
'Width': ...,
'Height': ...,
'Left': ...,
'Top': ...
},
........
},
{
'Timestamp': 456,
'Person': {
......
'BoundingBox': {
'Width': ...,
'Height': ...,
'Left': ...,
'Top': ...
},
........
}
]Aggregating employees per timestamp
Now, similar to what we did with all the faces, let’s aggregate the employees per timestamp.
As a quick reminder, in production code you would likely create a more generic function since although the APIs are different between the two jobs, the logic is the same.
However, for the sake of simplicity let’s keep it separate.
from collections import defaultdict
def aggregate_employee_faces_by_timestamp():
aggregated_employee_faces = defaultdict(list)
for employee in employees:
timestamp = employee['Timestamp']
face = employee['Person']
aggregated_employee_faces[timestamp].append(face)
return aggregated_employee_faces
aggregated_employee_faces = aggregate_employee_faces_by_timestamp()Now aggregated_employee_faces will contain array of employee faces objects per timestamp.
{
'123': [ {...all employee face objects in timestamp 123} ],
'456': [ {...all employee face objects in timestamp 456} ],
}Tagging employees in the generic faces pool
Now that we have the employee faces, we can tag them in the generic faces pool by correlating bounding boxes between identical timestamps.
But before writing the code, let’s understand what a bounding box is.
Bounding boxes
In computer vision, a bounding box is a rectangle representing an object’s location and size in an image or a video.
In most cases, bounding boxes are represented either by the top left (x1, y1) and bottom right (x2, y2) corners, or by the top and left positions alongside the width and height of the box.


Bounding box comparison
Unfortunately, at the time of writing this post, unlike get_face_search, get_face_detection does not return a face ID.
Thus, our only way to tag known faces from the generic faces pool, which also includes customers, is by comparing bounding boxes in each time frame.
To tag the employees in the generic faces pool, we need to iterate through the generic faces and compare the bounding boxes with the employee faces.
def tag_employees():
# iterate over the aggregated faces
for timestamp, faces in aggregated_faces.items():
# if no employee detected at a given timestamp, continue
if timestamp not in aggregated_employee_faces:
continue
# extract employee faces and the bounding boxes in the given timestamp
employee_faces = aggregated_employee_faces[timestamp]
employee_bboxes = [emp_face['BoundingBox'] for emp_face in employee_faces]
for face in faces:
# if the bouding box equal to the employee bounding box, tag the face as employee
if face['BoundingBox'] in employee_bboxes:
face['employee'] = True
tag_employees()At this point, the aggregated_faces object will contain the employee key for each face that was detected as an employee.
Now, we can move on to implementing an algorithm to detect whether a customer is interacting with an employee, and if so, whether the customer is happy.
Detecting whether a customer interacting with an employee
In order to determine whether a custom is interacting with an employee, multiple conditions should be met:
- The customer and the employee are in the same time frame
- The customer and the employee are in proximity in 2d
- The customer and the employee are in proximity in 3d (depth)
- The customer is facing the employee to a certain degree
- The customer or the employee are talking
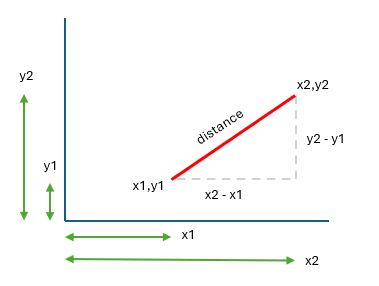
Determine 2D proximity - Euclidian distance
One of the indicators of proximity in 2D is the distance between the customer and the employee based on the bounding boxes.
To determine proximity, we can calculate the center of each bounding box and measure the distance between the two centers using the Euclidean distance formula.
In order to determine the x and y coordinates of the center of a bounding box, the following formulas can be used:
After calculating the center of each bounding box, we need to calculate their distance.
If we think of the image as a 2D plane, the distance between two points can be calculated using the Euclidean distance formula:
Let’s implement this in code:
import math
# calculate the center of a bounding box
def get_center(bbox):
return bbox['Left'] + bbox['Width'] / 2, bbox['Top'] + bbox['Height'] / 2
# calculate the distance between two points
def calculate_distance(center1, center2):
return math.sqrt((center2[0] - center1[0]) ** 2 + (center2[1] - center1[1]) ** 2)
# determine whether two bounding boxes are in proximity in 2D
def are_in_2d_proximity(bbox1, bbox2):
threshold = 0.1
return calculate_distance(get_center(bbox1), get_center(bbox2)) <= threshold
# this is a generic function that determines whether employee and customer are communicating,
# we will add more conditions soon
def are_interacting(obj1, obj2):
in_2d_proximity = are_in_2d_proximity(obj1['BoundingBox'], obj2['BoundingBox'])
return in_2d_proximity
# this is a generic iteration over employee and non-employees
for timestamp, people in aggregated_faces.items():
# this double loop is not very efficient but easy to understand
employees = [obj for obj in people if 'employee' in obj]
customers = [obj for obj in people if 'employee' not in obj]
# object to store employees interactions
employee_interactions = defaultdict(list)
for employee in employees:
for customer in customers:
if are_interacting(employee, customer):
# if given employee was interacting with given customer
# add the interaction, and it's quality
employee_interactions[employee['employee_name']].append({
'timestamp': timestamp,
'customer_emotions': customer['Emotions']
})We will soon add additional conditions to determine whether the employee and the customer were interacting,
however for now let’s clarify that the output of the main iteration will be employee_interactions objects with contents that looks like this:
{
'david_smith': [
{
'timestamp': 'timestamp1',
'customer_emotions': [
{
'Type': 'SAD',
'Confidence': 95.0
}
]
},
{
'timestamp': 'timestamp2',
'customer_emotions': [
{
'Type': 'HAPPY',
'Confidence': 65.0
}
]
}
]
}Based on this object, we can examine and improve employee interactions. However, before that, let’s add additional conditions to more precisely determine whether the employee and the customer are interacting.
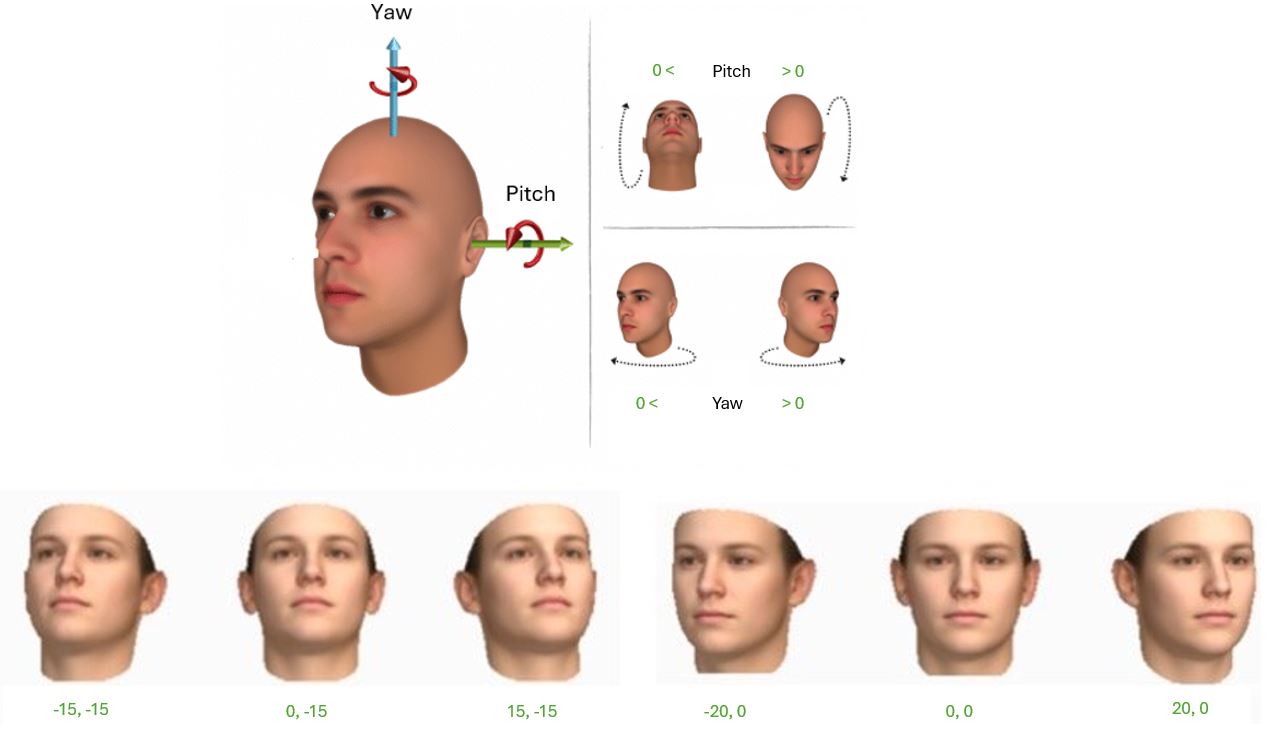
Yaw and Pitch degrees to determine whether the customer is facing the employee
Of course there is no guarantee that two people facing each other are interacting, nor does it mean that if they are not facing each other they are not interacting. However, it’s a reasonable indicator and we will use it to increase our confidence in the interaction detection.
Do determine whether the customer is facing the employee, we can use the Pose object returned by the get_face_detection API,
or more precisely the Yaw and Pitch degree values, which are specified in degrees and ranging from -180 to 180.
The API also returned a Roll value, but we will not use it in this case.
To demonstrate the concept, I’ve combined and edited nice illustrations by Tsang Ing Ren and Yu Yu from ResearchGate.
Now that we understand the concept of Yaw and Pitch, we can use it to determine whether the customer is facing the employee:
def are_facing_each_other(obj1, obj2):
# Define the thresholds for yaw and pitch differences
yaw_threshold=20
pitch_threshold=10
# Calculate the differences between the yaw and pitch angles of the two objects
yaw_diff = abs(obj1['Yaw'] - obj2['Yaw'])
pitch_diff = abs(obj1['Pitch'] - obj2['Pitch'])
# Check if the differences are within the specified thresholds
if yaw_diff <= yaw_threshold and pitch_diff <= pitch_threshold:
return True
return FalseAfter that, we will add are_facing_each_other to be part of the are_interacting function:
def are_interacting(obj1, obj2):
in_2d_proximity = are_in_2d_proximity(obj1['BoundingBox'], obj2['BoundingBox'])
facing_each_other = are_facing_each_other(obj1['Pose'], obj2['Pose'])Determine 3D proximity - BoundingBoxes size
Alright, so now we’ve determined the proximity of the bounding boxes in 2D and whether the customer is facing the employee. Next, we need to determine whether the bounding boxes are close enough in 3D space. For example, the following bounding boxes are close in 2D, but not in 3D:

To determine the 3D proximity, we can use the size of the bounding boxes and simply compare the width and the height of the box:
def are_in_3d_proximity(obj1, obj2):
width_threshold = 15
height_threshold = 15
height1, width1 = obj1['Height'], obj1['Width']
height2, width2 = obj2['Height'], obj2['Width']
# Calculate the absolute differences and compare them to the thresholds
width_diff = abs(width1 - width2)
height_diff = abs(height1 - height2)
if width_diff <= width_threshold and height_diff <= height_threshold:
return True
return FalseAfter that, we will add are_in_3d_proximity to be part of the are_interacting function:
def are_interacting(obj1, obj2):
in_2d_proximity = are_in_2d_proximity(obj1['BoundingBox'], obj2['BoundingBox'])
facing_each_other = are_facing_each_other(obj1['Pose'], obj2['Pose'])
in_3d_proximity = are_in_3d_proximity(obj1['BoundingBox'], obj2['BoundingBox'])Indication of talking - MouthOpen
Like the other features, an open mouth does not guarantee that the person is talking, but it’s an additional indicator of possible interaction.
When combined with the other features we checked, it can increase our confidence that there is an interaction between the employee and the customer.
Alongside BoundingBox, Pose, and Emotions, the get_face_detection API also returns a MouthOpen value, which indicates whether the mouth is open or not.
Let’s write a short code snippet to add this to our conditions:
def are_potentially_speaking(obj1, obj2):
return obj1['MouthOpen']['Value'] is True or obj2['MouthOpen']['Value'] is True
def are_interacting(obj1, obj2):
in_2d_proximity = are_in_2d_proximity(obj1['BoundingBox'], obj2['BoundingBox'])
facing_each_other = are_facing_each_other(obj1['Pose'], obj2['Pose'])
in_3d_proximity = are_in_3d_proximity(obj1['BoundingBox'], obj2['BoundingBox'])
potentially_speaking = are_potentially_speaking(obj1, obj2)Completing the are_interacting function
Now that we have all the conditions, we can complete the are_interacting function:
def are_interacting(obj1, obj2):
in_2d_proximity = are_in_2d_proximity(obj1['BoundingBox'], obj2['BoundingBox'])
facing_each_other = are_facing_each_other(obj1['Pose'], obj2['Pose'])
in_3d_proximity = are_in_3d_proximity(obj1['BoundingBox'], obj2['BoundingBox'])
potentially_speaking = are_potentially_speaking(obj1, obj2)
return in_2d_proximity and facing_each_other and in_3d_proximity and potentially_speakingCalculate employee performance
As explained in previous sections, now employee_interactions object should contain employee interactions list and customer emotions per each interaction,
and it should look roughly like this:
{
'david_smith': [
{
'timestamp': 'timestamp1',
'customer_emotions': [
{
'Type': 'HAPPY',
'Confidence': 55.0
}
]
},
{
'timestamp': 'timestamp1',
'customer_emotions': [
{
'Type': 'HAPPY',
'Confidence': 95.0
}
]
}
]
}Now we can calculate the final performance score for each employee (explanations are in the code comments):
# Emotions to performance score
emotions_to_performance_scores = {
'HAPPY': 1.0,
'SAD': -1.0,
'ANGRY': -0.5,
'CONFUSED': -0.2,
'DISGUSTED': -0.5,
'SURPRISED': 0.1,
'CALM': 0.8,
'FEAR': -0.5,
'UNKNOWN': 0.0
}
def calculate_performance_score(current_employee_interactions):
# set confidence threshold, if we don't reach it we can't suggest a performance score
confidence_threshold = 10
# set initial values for score and confidence
total_performance_score = 0
total_confidence = 0
# iterate over all interactions of the current employee
for interaction in current_employee_interactions:
for emotion in interaction['customer_emotions']:
emotion_type = emotion['Type']
confidence = emotion['Confidence']
# get performance score based on detected emotion type
emotion_score = emotions_to_performance_scores.get(emotion_type, 0)
# weight performance score by the emotion score multiplied by the confidence of the emotion
weighted_score = emotion_score * (confidence / 100.0)
# update the total values based on weight adjustments
total_performance_score += weighted_score
total_confidence += confidence
# If we have sufficient confidence, calculate the final performance score
if total_confidence > confidence_threshold:
final_performance_score = total_performance_score / (total_confidence / 100.0)
else:
final_performance_score = 'Could not determine'
return final_performance_score
employee_scores = {}
# iterate over all the detected employee_interactions
for employee, interactions in employee_interactions.items():
employee_scores[employee] = {
'performance_score': calculate_performance_score(interactions),
'supporting_data': interactions
}The output of employee_scores will be a dictionary with the employee names as keys, performance score and supporting data as values:
{
'david_smith': {
'performance_score': 1.0,
'supporting_data': [
{
'timestamp': 'timestamp1',
'customer_emotions': [
{
'Type': 'HAPPY',
'Confidence': 55.0
}
]
},
{
'timestamp': 'timestamp1',
'customer_emotions': [
{
'Type': 'HAPPY',
'Confidence': 95.0
}
]
}
]
}
}Now, one can use this information as actionable insights to improve employee performance and customer satisfaction.
I did clarify this at the start of the post, but this is not production ready code as it is too simplified and lacks error handling, scaling considerations and other important aspects of
production code.
However, this post gives a good starting point in using AWK Rekognition.