Speeding up spark SQL with adaptive query execution
Important Warning: This post was written a long time ago, and its contents and code may be outdated or no longer aligned with current industry standards. Please proceed with caution. :-)
- Intro
- Dynamically switching join strategies
- Dynamically coalescing shuffle partitions
- Dynamically optimizing skew joins
Intro
Spark version 2.x introduced CBO (cost-based-optimization) framework.
CBO collects and leverages different data statistics (e.g, row count, number of distinct values, etc.) in order to improve
the quality of query execution plans.
However, building a query plan based on static data which isn’t updated in runtime, comes with some drawbacks.
Some examples will be outdated statistics or inaccurate cardinality estimates.
This can lead to suboptimal query plans.
AQE (adaptive query execution) framework attempts to solve these issues by re-optimizing the query plans based on runtime statistics
collected during the execution.
So, what are the main features that AQE framework brings to the table?
Dynamically switching join strategies
Prior to AQE, one of the optimizations done by spark was switching to broadcast join when an
estimated size of one of the sides of the join could fit well into the memory based on a threshold configuration (default ~10mb).
One of the issues with this approach was that spark couldn’t take applied filters into consideration, so if a table couldn’t fit into the threshold before filtering,
spark wouldn’t attempt to broadcast join it even if it could after applying filters.
With AQE, Spark re-plans the join strategy in runtime based on up-to-date join relation size.
Dynamically coalescing shuffle partitions
Shuffle is one of key factors in a query performance, and one of the key factors for a performant shuffle is an optimal number of partitions. What is an optimal number of partitions? Well, that’s a hard thing to get.
- You need to be familiar with the data.
- Even if you familiar with it, we can always have an unexpected skew in production.
- Optimal partition number might change from stage to stage, and so on.
Eventually, If we’ll have too few partitions for the data at hand, we might encounter spills to disk and uneven distribution of work. If we’ll have too many partitions, we’ll end up with a lot of tasks and network overhead.
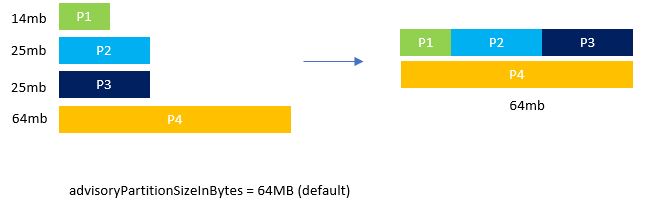
AQE Attempts to address these issues by re-optimizing the optimal number of partitions after every stage of the job, aiming for similar size between all the partitions, considering the definition supplied by the
spark.sql.adaptive.advisoryPartitionSizeInBytes (with some exceptions like parallelismFirst) parameter.
Dynamically optimizing skew joins
Data skew is one of the most frequent reasons for performance issues, especially during join.
While prior to AQE we had to always manually mitigate skew joins (repartitioning, salting etc.), AQE obsoletes some of this work.
AQE optimization detects skews based on shuffle file statistics and automatically splits large partition into smaller sub partitions, which will be joined
with the corresponding (after duplication) partition from the other side respectively.
Before AQE optimization:
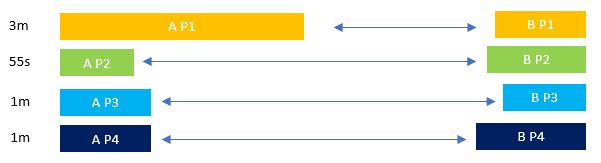
In this case, we will have 4 tasks, 1 task per partition. The longest task (A P1 to B P1) will take 3 minutes while all the others will take approx. 1 minute, resulting in a total execution time of 3 minutes.
After AQE optimization:
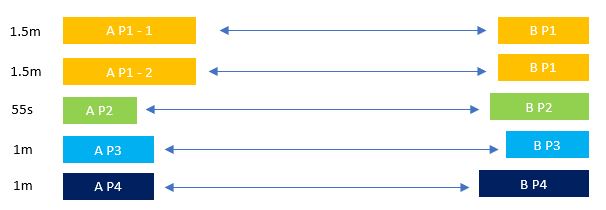
AQE Optimization will split ABP1 into 2 different partitions, duplicate BP1 and join between them, increasing the number of tasks to 5, but reducing allowing a better parallelism, thus reducing the overall execution time by half.