Extending Flyweight pattern ideas to improve system-wide performance and reduce costs
This post was written some time ago, and its content and code may be outdated or no longer aligned with current industry standards. Please proceed with caution. :-)
Intro
There are plenty of sources online explaining the Flyweight design pattern in depth.
The most common description of the pattern is that it designed to reduce memory footprint of a program without losing any capability.
But the ideas behind it can be extended to a broader, system-wide scale.
I won’t get into the depth of the design pattern itself (if you’re not familiar with it, you can check out a good explanation in wikipedia), but I will sum it up to a very simplistic explanation:
The Flyweight pattern suggests minimizing the memory footprint of a large amount of objects, by storing commonly shared data in external data structures, and share these data structures with the objects themselves.
Terminology wise, we’ll have:
- Intrinsic state, which refers to the commonly shared data.
- Extrinsic state, which refers to context related data, we can call it dynamic data.
A simple example for it can be bullets in a shooter game, an extrinsic state will refer to the x,y of the bullet location, while the intrinsic state will refer to the color, size and other constant properties of the bullet. We will have a lot of minimalistic bullet objects, which will refer to a single graphical representation object.
Taking the general idea to a system-wide level
Let’s say you’re working on a cyber-security system which monitors and ingests network traffic from 3rd party sensors, analyzes the traffic and reports suspicious activity. It’s simplified architecture will look something like this:
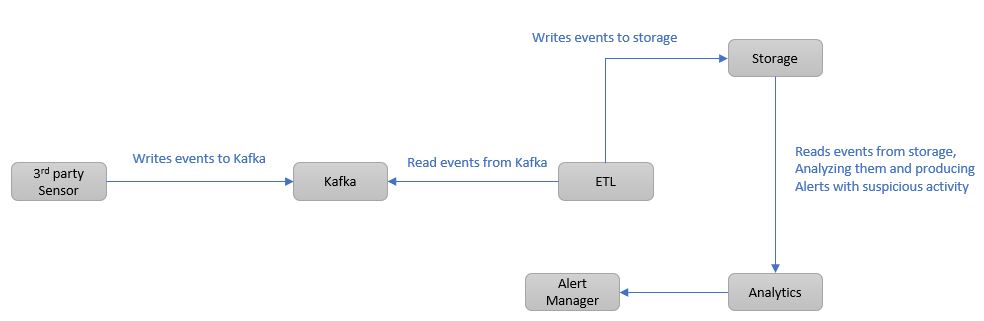
Let’s assume that one of the events the sensor records, is DNS lookups done by endpoints and servers in the network. The sensor enriches it with owner info - such as ASN, and produce it to Kafka, from which ETL reads the event and saves it to storage. The event structured something like this:
{
"event_initiator_ip": "1.1.1.1",
"type": "dns_lookup",
"domain_name": "www.google.com",
"record_type": "a",
"ttl": 5,
"address": "142.251.40.164",
"owner_asn_info": {
"ASNumber": "15169",
"ASName": "GOOGLE",
"RegDate": "2000-03-30",
"Updated": "2012-02-24",
"Ref": "https://rdap.arin.net/registry/autnum/15169",
"OrgName": "Google LLC",
"OrgId": "GOGL"
},
"owner_whois_info": {
"NetRange": "142.250.0.0 - 142.251.255.255"
"CIDR": "142.250.0.0/15"
"NetName": "GOOGLE"
"NetHandle": "NET-142-250-0-0-1"
"Parent": "NET142 (NET-142-0-0-0-0)"
"NetType": "Direct Allocation"
"OriginAS": "AS15169"
"Organization": "Google LLC (GOGL)"
"RegDate": "2012-05-24"
"Updated": "2012-05-24"
"Ref": "https://rdap.arin.net/registry/ip/142.250.0.0"
}
}For simplicity of the example, lets assume we’re not compressing, nor using better suited formats to store the data, and we’re just saving it as is in JSON format. This will cost us roughly 1kb per event. In a network with 10K/S lookups to google, it means a rough estimate of 864gb of daily data only for DNS lookups.
- It means 864gb worth of daily addition to storage
- It means that if we’ll attempt to write a daily scheduled analytic, it’ll have to handle 864gb of data
You probably already see where I’m going with this.
If we take a close look at the event data, we’ll see that the owner info is not context related, and probably won’t be frequently modified between each lookup event for the same domain. We can consider it as an intrinsic state.
If we change our ETL to work with a cache of ownership info, writing it to a separate intrinsic data storage only when needed, we can reduce the amount of data we need to store and process by roughly 84%.
Our updated architecture will look something like this:
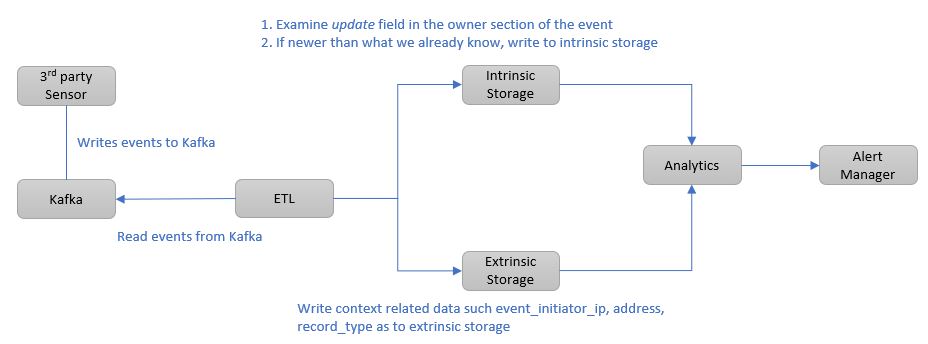
The majority of the data (extrinsic data) will be reduced to this:
{
"event_initiator_ip": "1.1.1.1",
"type": "dns_lookup",
"domain_name": "www.google.com",
"record_type": "a",
"ttl": 5,
"address": "142.251.40.164"
}Be careful with the tradeoffs
As you probably understand, separating the data to intrinsic and extrinsic states is not a cost free action. You need to consider your data and it’s usages before separating it.
In our example, the ETL will have to do more work before saving the data:
- Managing a cache, in memory or external
- Checking for existence of owner data and comparing the update dates
- Doing an extra store action in case of a new intrinsic info
A lot will be decided by the implementation.
For example, in our use case, we can decide that only common domxzxains (google, stackoverflow etc’) and their owner info will be go through intrinsic pipeline, and use in memory cache, which will mean two things:
- Working with cache will be extremely performant
- Storing most common domains will reduce the majority of the data, while taking relatively small amount of memory
Another thing to consider is the usage of the data, the analytics in our case -
can we preload the intrinsic data in the analytics? If not, will JOINing (with spark, for example) of small amount of intrinsic data
will be faster than working with 84% more data which is already in the same dataframes?