Make your Kubernetes workloads more robust with startup, readiness and liveness probes
Important Warning: This post was written a long time ago, and its contents and code may be outdated or no longer aligned with current industry standards. Please proceed with caution. :-)
- Intro
- What can go wrong?
- Problem #1 - replica changes in time of manual scaling, or even worse, HPA (horizontal pod autoscaling)
- Problem #2 - applicative errors that don’t crash the main process
- Enter kubernetes probes
- Setting probe configuration
- Types of probe actions
- HTTP action
- TCP action
- Command action
- Complete example
Intro
It’s no easy task to make distributed workloads robust and resilient. Kubernetes coming into our lives made this job a lot easier. But, like many things in the engineering world, good can become better.
Let’s take this a very simplified architecture of an online store backed up by an ML based recommendation system.
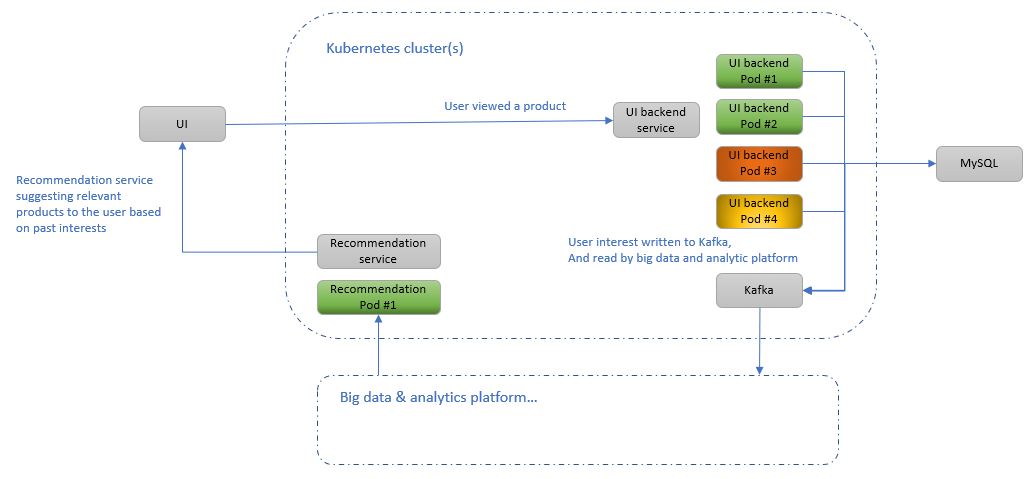
As shown in the diagram, user interactions such as viewing a product sent to a UI BE.
UI BE writes the event to kafka.
A big data & analytic platform collects the data from kafka, doing some magic and produces list of recommended
products for the user, based on his past interests.
What can go wrong?
As you probably know, by default, K8S control loop will consider a container as functioning as long as the main process is up and running.
But, up and running not necessarily means that a container is ready to receive requests.
As you can see, UI BE depends on MySQL DB. For the sake of the example, let’s say that on instantiation,
each UI BE pod needs to bring some data from MySQL to memory to serve requests.
Problem #1 - replica changes in time of manual scaling, or even worse, HPA (horizontal pod autoscaling)
You got to a point where you need to change the replicas number of your pods. This can be a simple case where your store gained popularity, and you need to add more replicas to cope with the increasing demand, or it can be a more complex case, where you’ve running in a cluster with configured HPA (Horizontal Pod Autoscaling).
If we’ll get back to our example, once your server and application are running, from K8S perspective, the pod is ready to receive requests. Every time the UI will send a recordable action by the user (e.g, product view) - the BE service will proxy the request to the pod in a round-robin (by default) manner. If the request will be proxied to a replica where the main process is running, but the connection to DB wasn’t established or the data required to serve the request still was not loaded to memory, the request will fail, and the data will be lost or a retry mechanism will need to be implemented.
While this might be an edge case if you do manual scaling, if HPA is configured in your cluster, which means that replicas will be changed quite frequently - your workload will be extremely unstable.
Problem #2 - applicative errors that don’t crash the main process
Let’s say one of your containers encountered a critical applicative error which makes the application instance unusable, while the main process is still active. Same as before, all events proxied by the UI BE service to the pod with the unusable application, will be lost or will have to be retried.
Enter kubernetes probes
Basically, we need an additional indication that our pods are ready to receive requests, besides the main process state. For that, Kubernetes provides us with different kind of probes:
- Startup
- Liveness
- Readiness
To make it easy to understand, let’s create a comparison table:
| Name | When to use | Action on failure | When it runs |
|---|---|---|---|
| Startup Probe | When you have a slow loading container, and you wish it won’t receive traffic until your custom logic indicates it’s ready to serve requests. | Service won’t send traffic to the pod | Only on startup |
| Liveness Probe | When you want periodic liveness checks that your container is up and running and can serve incoming requests | K8S will kill the pod and attempt to spawn a new one | Throughout the entire life of the pod |
| Readiness Probe | Very similar to liveness probe, but the action taken on failure is different | Service won’t send traffic to the pod | Throughout the entire life of the pod |
Setting probe configuration
| Parameter | Description | Default |
|---|---|---|
| initialDelaySeconds | How long to wait (in seconds) after the container has started before liveness or readiness probes are initiated | 0 |
| periodSeconds | Probe interval (in seconds) | 10 (min 1) |
| timeoutSeconds | Timeout configuration for the probe (in seconds) | 1 |
| successThreshold | Minimum consecutive successes for the probe to be considered successful after having failed | Must be 1 for liveness and startup probes |
| failureThreshold | How many times a probe should run before failure is declared and an action on failure will be executed (as described in the table above) | 3 |
Types of probe actions
There are 3 types of probe actions:
- HTTP
- TCP
- Command
HTTP action
Kubelet will send an HTTP GET request to an endpoint, and will define any status code from the 200-300 ranges as a success.
HTTP Can be configured with additional parameters:
| Parameter | Description | Default |
|---|---|---|
| host | Hostname to connect to | Pod IP |
| scheme | HTTP or HTTPS | HTTP |
| path | Path on the server | - |
| httpHeaders | Custom headers (e.g, Authorization header) | - |
| port | Access port | - |
TCP action
Just checks a successful TCP connection. If a connection is established the probe considered successful.
Command action
Runs a shell command inside the container. On 0 exist code, action will be considered successful.
Complete example
An example for 3 different type of probes, each of them with a different action method.
apiVersion: v1
kind: Pod
metadata:
name: probes-demo
spec:
containers:
- name: probes-demo
image: your-image
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /health
port: 80
initialDelaySeconds: 2
periodSeconds: 2
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
readinessProbe:
exec:
command:
- /my-health-cmd
initialDelaySeconds: 5
periodSeconds: 5
startupProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20